Want to learn about artificial intelligence but feel overwhelmed by the jargon? This article explains the four main learning paradigms in machine learning in simple terms, using relatable examples. We'll also provide curated learning resources for further exploration.
The Four Main Machine Learning Methods
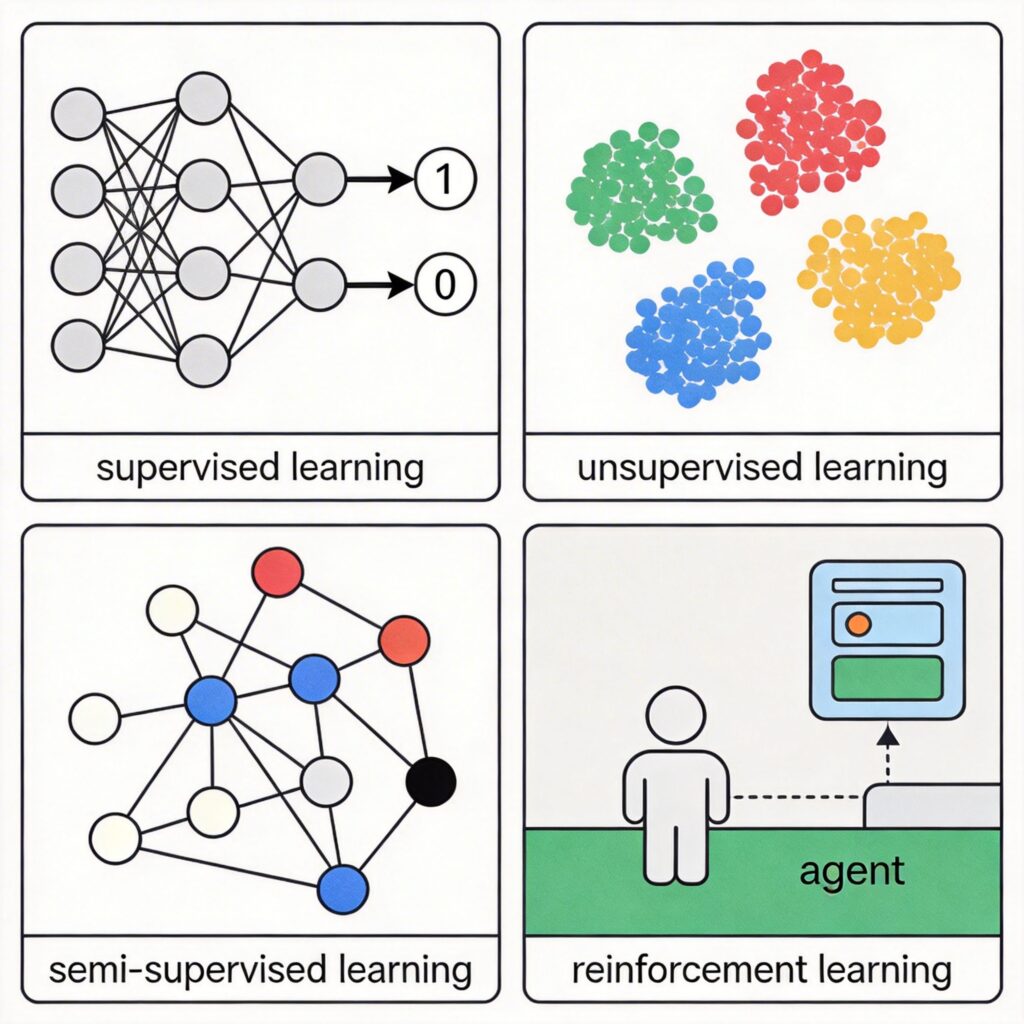
Based on the type of training data and methodology, machine learning is primarily categorized into four types:
- Supervised Learning
- Unsupervised Learning
- Semi-supervised Learning
- Reinforcement Learning
This classification applies to both traditional machine learning and deep learning.
1. Supervised Learning
Supervised learning uses data with explicit "correct answers" (labels) to train a model. For example, to train a system to identify photos containing your parents from an album:
Step 1: Data Preparation & Splitting
First, label all photos indicating which contain your parents. Then split this labeled data into two sets:
- Training Set: Used to train the model.
- Validation Set: Used to evaluate the model's accuracy after training.
Mathematically, the goal is to find a function that takes a photo as input and outputs "Yes" (1) or "No" (0). This is a classification problem. If the output is a continuous value (e.g., predicting credit card repayment probability), it's called regression.
Step 2: Model Training
During training, each image is input into a neural network. The network calculates a prediction (involving weights, activation functions, etc.). Since we know the true label, we can calculate the deviation between the prediction and the truth, measured by a cost function (or loss function).
The backpropagation algorithm then passes error information backward through the network to adjust neuron weights and biases, minimizing the cost function, often using optimization methods like gradient descent.
Step 3: Validation & Tuning
The reserved validation set tests model performance. To improve results, we adjust model hyperparameters (e.g., number of network layers, neurons, learning rate). Training and validation often alternate.
Step 4: Application
The trained model can be integrated into an application, providing an API like ParentsInPicture(photo). When called, the model computes and returns a result.
The main challenge is the high cost of data labeling. Thus, it's used where labeling benefits far outweigh costs, such as in medical imaging for cancer diagnosis.
2. Unsupervised Learning
Unsupervised learning uses unlabeled data. The system must discover inherent structures or patterns. Common tasks are clustering and anomaly detection.
Example: A clothing company wants to design T-shirt sizes (XS, S, M, L, XL) but doesn't know specific measurement ranges. They can collect user body measurements and use a clustering algorithm (like K-Means) to naturally group users into clusters, each corresponding to a size.
A famous case is the Google Brain "YouTube cat" research. The system watched vast amounts of YouTube videos without any "cat" labels. Through unsupervised learning, it automatically categorized video content and successfully identified "cats" and thousands of other object categories.
Key unsupervised learning techniques include:
- Autoencoders
- Principal Component Analysis (PCA)
- K-Means Clustering
- Generative Adversarial Networks (GANs)
3. Semi-supervised Learning
Semi-supervised learning sits between supervised and unsupervised learning. It uses a small amount of labeled data and a large amount of unlabeled data. This significantly reduces labeling costs while achieving performance close to pure supervised learning.
Intuitively, even without precise labels, understanding the data distribution (from unlabeled data) helps the model better define boundaries and improve generalization.
In practice, it effectively extends model classification capability. Research shows for some tasks, semi-supervised learning with just 30 labeled samples per class can match the performance of supervised learning with 1360 labeled samples per class, allowing rapid scaling to more categories.
4. Reinforcement Learning
Reinforcement learning (RL) enables an agent to learn by interacting with an environment. It doesn't rely on labeled datasets but uses reward and penalty signals to guide learning. This is similar to a "hot and cold" game: you get "hot" (reward) feedback as you move closer to a goal, and "cold" (penalty) otherwise. The agent's goal is to learn a policy that maximizes long-term cumulative reward.
Unlike supervised learning where the correct answer is immediate, RL feedback is often delayed and sparse.
A milestone was DeepMind combining deep learning with RL (Deep RL) to create an AI that plays multiple Atari games. It excelled at games like Breakout but initially struggled with games like Montezuma's Revenge that require long-term planning, due to sparse rewards. Later research solved this by introducing natural language instructions (e.g., "climb ladder," "get key") as extra guidance.
RL has broad applications in gaming, robotics, autonomous driving, and more.
Learning Resources
Here are resources to deepen your understanding:
- Stanford Deep Learning Tutorial: Covers supervised & unsupervised learning with code. http://ufldl.stanford.edu/tutorial/
- Neural Networks & Backpropagation Intro:
Algobeans: https://algobeans.com/2016/11/03/artificial-neural-networks-intro2/
Michael Nielsen: http://neuralnetworksanddeeplearning.com/chap2.html - Unsupervised Learning Course (Udacity): https://www.udacity.com/course/machine-learning-unsupervised-learning--ud741
- Semi-supervised Learning Tutorial by Prof. Xiaojin Zhu.
- Reinforcement Learning:
DeepMind Intro: https://deepmind.com/blog/deep-reinforcement-learning/
Book: Reinforcement Learning: An Introduction (Sutton & Barto): http://incompleteideas.net/sutton/book/the-book.html